The State of CoApp
Oct 02 2013 by Garrett Serack @fearthecowboy
Tags news
I know I've been kinda quiet of late; lemme catch y'all up.
What's up with CoApp tools?
Right around early July, we reached a pretty stable milestone with regards to the CoApp tools; we had noticed that there were some particularly nasty issues when we started to produce packages with too many variants, and each variant had a lot of files, we noticed that the redist package was getting far to big. In one case, it was over a gigabyte compressed.
So, we knew that we needed to split stuff up in a finer grained manner, and so over the course of the summer (when I wasn't distracted on other things), I reworked the tools to generate a separate redist package for each variant. This also required some significant changes to what happens at build time (which it now downloads and overlays the redist package when you need it). This makes it so you never have to download the bits for all the variants that you never use.
I also added a cmdlet to upload a whole set of packages to a NuGet server, so you don't have to do that all by hand (which would totally suck when you have 70 different variations!)
I'm publishing this as a Beta later this week (update using the update-coapptools -killpowershells -beta command) -- I'll put out another post when I do that.
What's the future of the CoApp tools?
Well, we're going to continue to support all the work we've done (as its still the only way to build VC++ NuGet packages that support many variants) and over the course of the year, continue to add a few more features.
As for the future of packaging on Windows in general, I had some ideas that forced me to re-evaluate my ideas and rethink how to get what we all want...
Where's this all goin'
So, back in August I started looking at what I was going to accomplish over the next year or so, and I thought it would be a good idea to try and see if I could get some of the CoApp package management ideas put into Windows itself (hey, it'd be kinda nice to be able to do apt-get style-stuff and have that built into the OS)
I had proposed some of this at the beginning of the product cycle for Windows Blue (Server 2012 R2/Windows 8.1) but it was a little too late in the planning cycle, and I gave too-grand of a vision.
I finally came to full understanding of some advice my pappy once told me: "The secret to success is to find someone else to care what you care about, and make it their problem." ... I looked at him like I understood what he meant, but he could tell that I was just paying lip service. He then said "Try it this way: Set the building on fire, take someone else's stuff into the building with you, and then cry for help"
The one truth that I do know, is: Setup ain't sexy Nobody is ever interested in 'fixing' software installation, because they never believe that it's a problem worth solving. Those of us who see it as important-or at least, a gateway to achieving other things-are left to chip away at it on the sly.
This year, I took a different approach.
First, find a building I could set on fire.
I sat down and thought "What's the smallest, useful thing that I can do that I can get done in time to ship in the next version of Windows?"
Instead of trying to get someone to buy into building some new packaging scheme into Windows--which only serves to get everyone who makes something that it would compete with all angry--I decided to flip the idea on it's head.
What if we had a set of interfaces (APIs, Managability Interface and Cmdlets) that just back-ended to any package management system (or anything that can look like one). Essentially a meta-package-manager that unifies everything together. Make the back end pluggable, so that any package management system can be plugged into it, regardless of how it's implemented, it's existing limitations, or how it accomplishes it's tasks.
Then build the interfaces on top of that, so that anyone who needs to perform a given task can use a single set of commands (or APIs) to make that happen.
Second, track down the people who's stuff I can grab.
We proceeded to find as many people inside Microsoft who have some tangential relationship to Software Discovery, Installation, and Inventory (SDII) and get them to buy into the dream. Everyone who deals with part of this problem generally only does so because they have to, so if we can get them to hook into this, they'll get the benefits without having to do all the ground work to pull it all together.
Tracking down everyone we could in the packaging, software installation, and inventory space was a ton of work, but we've talked with just about everyone... I think.
Third, run into the building.
One group I ran into, was some folks involved in an ISO standardization of 'Software Identity Tags' (aka SWIDTAGS) which is a spec for a way of documenting software so that eventually you could scan a system and find out what is installed, and how it all relates to each other.
This was a great thing! Except, that I needed a much better format than they were coming up with.
Jumping onto an ISO committee
This is how I got my butt onto the ISO 19770-2 working group, in where I brought in the other scenarios that I wanted to support, got them to accept them, and proceeded to do a blitz of rewriting to the schema in time to get it proposed as the next Committee Draft, less than a month after I got involved!
(As a side note, try not to join an ISO working group 1 month before they submit a CD; making dramatic changes this quickly can make people pretty panicky!)
Finally, cry for help!
I'm now at the point where we are bringing all of this together to get the approval to put this into the next version of Windows. Once we've got it that far, I'll have a ton more details (and hopefully some mind-blowing announcements that make this post seem like going for ice cream).
I really wish I could give you more details at this point, but you'll just have to hang in there until I get past this stage.
-G
View Comments
Northwest Hackathon!
May 06 2013 by Garrett Serack @fearthecowboy
Tags news
Northwest Open Source Hackathon
What is it:
An opportunity for Open Source Developers to come together, and get some things done. We’re bringing folks together from different open source projects like NuGet, CoApp, and Orchard along with engineers from some Microsoft Product groups.
With the NuGet 2.5 release, NuGet now supports building Native libraries for C/C++, so we’re bringing special attention to hacking away on producing NuGet packages for as many open source projects as possible. Don’t know how to use NuGet? Come and Learn? Want to make some packages? Come on out!
Want to work on some other Open Source stuff? Cool, that works too!
Prizes, drinks, food, and whole lot of code!
When:
Friday May 10th and Saturday May 11th
10am till we drop!
Coming Soon:
We're going to also try to broadcast it all live too, so that those who can't make it can participate on line!
Where:
Microsoft Campus, building 99 -- Room 1919
14820 Ne 36th St, Redmond, WA
http://binged.it/12L1qfT
How much does it cost:
FREE for anyone to attend.
Who is invited:
Anyone interested in hacking away on Open Source software, hanging out, munching on some food, and having a good time.
Sponsors:
Microsoft, Outercurve Foundation
Registration:
View Comments
Announcing CoApp PowerShell tools for NuGet 2.5
Apr 26 2013 by Garrett Serack @fearthecowboy
Tags news
Let's start with the Awesome -- today, in collaboration with the Visual C++ team and the NuGet team we're pleased to announce the availability of NuGet 2.5 and the CoApp PowerShell tools beta.
This brings the power of NuGet's package management for software developers to C/C++ developers for the first time.
Getting Started building C/C++ packages
Before I ramble on into the sunset, let point out some stuff
We have:
- Tutorials and
- online reference pages,
- and even a video tutorial you can watch.
When you need a bit more help...
Tim and I are nearly always hanging out during the day on IRC at irc://irc.freenode.net/#coapp
When stuff breaks, you can even file a bug.
And if you're at you're wit's end you can:
- tweet me @fearthecowboy
- or heck, even just email me directly: garretts@microsoft.com -- (brave, eh?)
And one more thing...
Open Source Hackathon
If you're in the Pacific Northwest, or can be on May 10th and 11th, we're holding a free-to-anyone Open-Source Hackathon where the NuGet folks, the CoApp folks and whomever else I can get to show up, will be hanging out, where we'll be working hard to produce packages for NuGet.
We have an open invitation for everyone to come and help us out, or show up and hack away on some other bits of open source software. Food, drinks, fun... what more could you want?
And now, the rest of the story.
==================
It's been a long time...
Up till now, NuGet has exclusively supported .NET and Web developers in packaging reusable libraries and components. CoApp's original goal was to provide this for native developers, and while we were making great headway on this, I was forced to think about somethin' my pappy always used to tell me: "If you find yourself in a hole, the first thing to do is stop diggin'."... The trouble is, your not always sure you're in a hole until you get it fairly deep.
So, last fall, I stopped coding for a bit... I looked long and hard at NuGet and then it hit me--we need to mesh with these folks. They've got the integration with Visual Studio, they've got great package discovery and a phenomenal number of packages. We don't need a second way to do this, we need there to be one great way for developers to get packages and install them regardless if they are Native or Managed developers.
At that point we started gettin' together folks all around and take a long hard look if NuGet could be used for packaging native libraries. Of course, C/C++ libraries are nothing like .NET libraries. While .NET developers have many different .NET frameworks to deal, with the clean way that .NET assemblies work, the problem scope is at least somewhat manageable. In the native world, we have header files, .LIB files, .DLLs ... and on top of that we have so very many different build variations. Platform (x86,x64,Arm,IA64) , Toolset (VC11,VC10,VC9,VC8,VC7,VC6,GCC... ), Configuration (Release,Debug), Linkage (Dynamic, Static, LTCG, SxS), Application Type (Desktop, WinRT, Phone, KernelDriver, UserModeDriver), and even CallingConventions (cdecl, stdcall, etc). Worse yet, individual libraries can have their own variants--sometimes pivoting on things you could never predict.
We took a long hard look at the ExtensionSDK model, and tried really hard to intersect that with NuGet, but there were far too many complications and scenarios that we were not sure we'd be able to handle. Took a couple steps back and try again.
If we kept the things that NuGet had to change down to an absolute minimum, we'd have to make sure that when packages got installed Visual Studio projects could easily integrate things like Include folders, Link libraries, managing outputs and content inclusion, and ... really, anything else the package creator needed to do to let someone use the fruits of their labor.
I knew this meant creating MSBuild project files inside the package. Now, if you've ever taken a long hard look at MSBuild, you'd realize that it's an amazingly powerful build system, but driven by a XML-based format that can be ... tricky to play with. Hand-crafting these files is essentially a non-starter, since the complexity of what the package creator has to do grows exponentially as the number of different variations grows. Never mind the fact that simple mistakes are easy to make in XML, and you have to have a fairly intimate knowledge of the format to make sure it's going to work for a wide audience.
==================
Gettin' from there to here...
I was pretty sure that I could generate MSBuild project files, but the trick was making it easy.
In January of this year, I started sketching out what information a packager would need to specify. And how could they articulate that information in a way that wasn't burdensome? And just how are we going to make it so that we can have a completely flexible means for packagers to say "these files are for this purpose, but only when this set of configurations is true ?
Earlier CoApp tools have used a file format that we called "Property Sheets" -- it's an evolution of an idea that I had years ago of using a format like CSS style sheets. It's far more readable than XML, and not just simply a data serialization format like JSON -- the structure of the document imparts meaning. Plus, the parser can be made extremely flexible, which makes it easier for humans to type stuff in, since they don't have to follow excessively pedantic rules for quoting values, or using , in a list where ; could be just as recognizable. I also knew that I needed to be able to map concepts in the Property Sheet to an arbitrary model like MSBuild, without having to modify how the MSBuild data model worked.
The rewriting I had to do, would take me about two or three weeks I figured, but turned out to be closer to 8 or 9. After that, it's all downhill, right?
==================
But our time is finally here...
At that point, I had a rough generator working, and we were rapidly approaching the NuGet 2.5 release date. The NuGet folks have been absolutely awesome in making sure that we're gonna make all this work, and I don't want to drop the ball. Tim and I have been workin' like crazy to try and deal with all the different scenarios, and even though we're aware of pretty much all of them, we were still fighting to actually vet and validate them. And it seems that each one has it's own quirks, and requires yet another special condition or specific generation feature.
Yet, we've prevailed. We've published the tools, and while there are still many things to add, fix and enhance, I think we're finally on solid ground.
View Comments
Northwest Hackathon Announced!
Apr 19 2013 by Garrett Serack @fearthecowboy
Tags news
Northwest Open Source Hackathon
What is it:
An opportunity for Open Source Developers to come together, and get some things done. We’re bringing folks together from different open source projects like NuGet, CoApp, and Orchard along with engineers from some Microsoft Product groups.
With the NuGet 2.5 release, NuGet now supports building Native libraries for C/C++, so we’re bringing special attention to hacking away on producing NuGet packages for as many open source projects as possible. Don’t know how to use NuGet? Come and Learn? Want to make some packages? Come on out!
Want to work on some other Open Source stuff? Cool, that works too!
Prizes, drinks, food, and whole lot of code!
When:
Friday May 10th and Saturday May 11th
10am till we drop!
Where:
Microsoft Campus, building 99
Redmond
How much does it cost:
FREE for anyone to attend.
Who is invited:
Anyone interested in hacking away on Open Source software, hanging out, munching on some food, and having a good time.
Sponsors:
Microsoft, Outercurve Foundation
Registration:
You can register online for the Hackathon--or, even better, register for both the Hackathon and the OuterConf conference!
View Comments
Trust, Identity and Stuff (uh, packages).
Apr 04 2013 by Garrett Serack @fearthecowboy
Tags news
A few weeks back, Phil Haack wrote blogged about "Trust and Nuget" in which he brings to light the terribly complex issues with how to know when to trust a given package or not.
Having spent a sizeable amount of my career working in the digital identity ecosystem, I feel like I've got more than a couple of ideas to throw at the problem, and I think that first thing to do is ensure that we're trying to solve the right problem.
Phil is fairly correct in asserting the means by which we implicitly (or explicitly) decide if a particular peice of code is worth trusting. Let's pivot a bit on his criteria, and see if we can't flesh it out a bit.
Identity
First, Phil asks the question "Who is the author?" - this would of course, appear to be the real central concept that we're basing our decisions off of. Well--sortof. We really care about who is the publisher of a particular piece of software for really only a few reasons.
Up front, is to be able to make a valid 'trust' decision--the idea of to what degree to trust that particular piece of software. Let's come back to that one in a moment.
The other half of the identity question boils down to blame or recourse. If something does go wrong, exactly who can I point the finger at, and what can be done about it?
Hmmm. That's a loaded question. Generally, in the opensource ecosystem, software is nearly always left without warrantee, so if there is simply a bug or failing in the software, I'd at least like to contact the author to get them to fix it.
Now, if there is malignant intent buried in there, we'd sure love to be able to smack someone around (figuratively!), or at the very least stop them from further distributing their smelly pile of manure.
But basically, Identity is mostly used as a factor in our calculations for determining whether we want to actually run that software. But how do we use it as a factor?
Dispelling a myth: Isn't Identity established with a Certificate?
Certificate Authorities (CAs) would have you believe that it does but in reality, the use of 'certificates' (ie, code-signing certificates and SSL certificates) just combines a couple things:
- Public-key cryptography -- the ability to digitally sign and verify that given message was produced by the holder of the private key.
- An assertion of claims by one holder (the CA) of a private key about another (the 'Subject' -- either an organization or a person).
So the certificate contains a bunch of properties--assertions by the CA, about the Subject--plus the public-key of the Subject, so that when the Subject signs something else, we can mathematically validate the message can only have come from that Subject.
Uh, why exactly would we trust the assertions of the CA? Who died and made them the king of everything? Well, In Windows, Microsoft includes the 'Root' certificates from a bunch of CAs that have a well-documented and verified process that they use to validate other's identities. In essence, you're trusting Microsoft to validate the CAs and therefore are trusting the CAs to validate others.
Which means that by virtue of validating the signatures of a bunch certificates, we're virtually establishing the identity of a person or organization, and generally, this is all we've ever been given as a deciding factor in 'trusting' someone.
Trust?
Trust is the word that a lot of people throw around, like there is some universal truth of trustworthiness, when really trust is a very personal decision, and subject to change one way or another depending on context and opportunity.
Anyway, getting back to the idea of "to what degree to trust that particular piece of software?" ... let's break this down into a few more questions:
"Can I run this piece of software safely" (probably the most important)
Highest on my list, it's easy to see that I'd rather not even touch something that was intending on stealing my data, or compromising my security. I'm assuming that Phil was refering to this when he asked "Is the author trustworthy?"
"Is this the actual software that I'm looking for"
This looks to establish the actual pedigree of the software, and is asserted by Phil's third question "Do I trust that this software really was written by the author?" If you know that a given piece of software is given to you by Microsoft or IBM or Intel, it means an awful lot more than if it comes from "FlyByNightCrapware, Inc."
"Will this software perform to the level that I need"
This is partially related to the previous one, but is a feeling of quality -- Even if the software is safe to use, will it do what I need it to? Should I even bother?
Perhaps we should think of 'trust' the same way that we think of the velocity of a car--it really only has significant meaning at a given point in time (where and when we examine it), and examining it after the fact only tells us the state at that given point.
If we think of the Context of a particular use as :
Context = WhereImUsingIt + WhenImUsingIt + WhatImUsingItFor
and Trust could be:
Trust = Context * Reputation
Then to determine trustworthiness, the only thing we have to figure out is-- what is the Reputation of the publisher.
Ah, Reputation
Phil makes some excellent points regarding how he establishes the reputation of a given publisher--associating accounts from many services (GitHub, Twitter, etc) and making a value judgment there.
Unfortunately this is a manual process, and engineering an automated system that isn't able to be gamed is extremely difficult to pull off.
And he's right, we need to piggy-back on another verification system.
It turns out that Digital Signing is the right answer.
What!? Didn't he say that it's not?
Yeah, but before we attempt to refute his reasons for saying that, let's see what Digital Signing does get us:
A method of using public-key cryptography to sign stuff
Virtually everything that we need to be able to verify (EXEs, DLLs, MSIs, Zip files, .nupkg files, PowerShell Scripts, etc) are directly able to be digitally signed and validated with existing tools. No new technology is needed. No special environments. It's all there, we've just been ignoring it for a long time.
A method for establishing an Identity (but not reputation)
Even though someone's Identity isn't their Reputation , we still require that someone assert who they are before we can make judgments about if we trust their code. At the very least it gives us the opportunity to find them, and go from there.
But even if it didn't it at least gives us the ability to determine that a given version of a package is produced by the same person that produced the last one. Even if I don't know who Bob Smith is, if I have package signed by him, and he issues an newer one, I can easily verify that it is from the same person, so I'm welcome to trust it as much as the one he issued before.
So, about those problems?
Ah, righty-so... There are a couple little gotchas, but nothing that can't be addressed, which at least provides something better than DOING NOTHING AT ALL.
The Cost and Ubiquity Problem
Yes, Digital Certificates issued by CAs are expensive. Prohibitively expensive for general adoption. They are OK for organizations that want to shell out a few hundred bucks a year for it, but private individuals are cut out of the game.
Waitaminute.
Would it shock you to know that there is a CA that doesn't charge for issuing certificates, and is handled in a method like a Web of Trust?
A Free Web-of-Trust style CA (see Wikipedia article)
CACert.org is a is a community-driven certificate authority that issues free public key certificates to the public (unlike other certificate authorities which are commercial and sell certificates).
These certificates can be used to digitally sign and encrypt email, authenticate and authorize users connecting to websites and secure data transmission over the Internet. Any application that supports the Secure Socket Layer (SSL) can make use of certificates signed by CAcert, as can any application that uses X.509 certificates, e.g. for encryption or code signing and document signatures.
What's the catch?
The catch is, the root certificates aren't distributed with Windows. That's ok, because they can be easily distributed with the software that needs them (ie, NuGet and/or CoApp) They don't even need to be installed into the Root Certificate Store, we can just have them on hand to verify that a particular certificate was issued off the CACert root cert.
Still, it gets us past the whole cost-as-an-issue problem.
The User Interface Problem
Oh, Right....So, becuase we don't have adequate UI to ensure that the user can make Reputation judgements for themselves is a reason not to sign packages?
Isn't that kinda like saying "We don't have cars, so why bother building roads?"
Shouldn't we start laying the groundwork where we can encourage (and eventually require) people to sign their packages, and build the reputation/trust resolution on top of that? The fundemental infrastructure for handling digital signing is pretty damn good. All we have to do is begin moving towards a model where we can help the user make the decisions for themselves.
TL;DR
- Digital Signing of packages, binaries, etc is very well handled with the tools and infrastructure of X509 Certificates.
- CACert.org can effectively provide the infrastructure for identifying individuals in a Web-of-Trust model, free of charge.
- Implementing Digitial Signing support today, puts us on the track for managing trust and reputation in a reliable fashion in the future, without having to "invent" new models at all.
View Comments
The long awaited "Just what the heck *are* you doing?" post...
Mar 27 2013 by Garrett Serack @fearthecowboy
Tags news
Howdy!
I've been heads down working on stuff for a while now, and I'm finally to a point that I think I can safely share what's going on, just where exactly we are, and what you can now play with. I didn't expect that it would take this long to get to this point, but like my pappy says "life can be kinda like a mule--sometimes it does what you're expectin' for so long, you forget that sooner or later, it don't like that" ...
Regardless, I think we're finally gettin' back on track.
Aligning ourselves with the most-popular library package manager
A few months back, I mentioned that we were altering our goals a bit, most notably to fit inside this global community.
After taking a long hard look at NuGet--most notably, its great Visual Studio integration and its rather massive uptake--we made the decision to try to unify these aspects of development on Windows, rather than attempt to fracture them further. Working closely with the NuGet and Visual Studio teams, we figured out what needed to be changed in order to support NuGet-style packages for native libraries.
How hard can that be?
.NET languages share code amongst themselves as assemblies -- files that contain the linker metadata, the referential information (what functions are in the file, and what parameters they need), dependency information, and finally, the executable code itself--all wrapped up in a single file. NuGet leveraged all that, and did all the heavy lifting for transporting collections of those assemblies around, and wiring up the references.
Native Libraries (C/C++) on the other hand, are far more complex to share and consume. Even just the wide variety of files that are necessary to share (.h/.hpp, .lib, .dll, doc files, etc...) make it challenging to package up and move around. Worse yet, in order to use a library that someone else produces, you need to at the very minimum do a ton of tweaks to the consumer's project file to add in directories to search when #includeing header files, sometimes additional #defines are required, which .lib files to link with, and how to get the redistributable .dll files into the output folder.
Compounding the problem
Solving that in a flexible and reusable way is difficult enough, but then you have the pile of straw that breaks the horse's back--for a given library, you have many, many, many ways to pivot on variants of that library:
| Pivot | | Typical variants | |
|---|
| Platform | | x86, x64, IA64, ARM, Any | |
| Linkage | | Dynamic, Static, Side-By-Side, LTCG* ... | |
| Compiler/Toolset | | VC6, (VC7, VC8), VC9, VC10, VC11, GCC, ... | |
| Threading | | Multi-threaded, Single-threaded... | |
| Configuration | | Release, Debug, Optimized... | |
| AppType/Subsystem | | Console,Windows,Win8AppStore,Driver... | |
Yeah, sure, not every library has every variant of every pivot. But it's clear that enough do that we'd better make sure that library publishers can arbitrarily create variants for every different way of packaging their library.
Where the meek get pinched, and the bold survive.
After going around in a few circles, it turns out that the changes to NuGet that we needed weren't all that big--the secret sauce for how NuGet can tell a consuming project where to get the instructions on what to do with an whole pasture full of files, is pretty easy. Allow individual packages to specify an MSBuild file for inclusion into the consuming project--typically these end in .targets or .props -- regardless what they are called, they can be added to the consuming project fairly trivially, and leverage MSBuild and Visual Studio to wire things up.
Easy then, right?
Well, except MSBuild files are terribly complex. And worse on an order of magnitude for every different pivot you want to support.
Solving for 'X'
CoApp already started down this path--although our model was to generate fine-grained packages, and try to do a Visual Studio plugin that would try to handle these things. We had already started shallow-forking libraries to create packages, and had scripted up a hundred or so do to precisely this. We had a tool (Autopackage) that would do all the heavy lifting for generating our packages, starting from a minimal amount of information about what was being packaged up.
We took a step back and looked at what we needed to produce, and I started working on a whole new Autopackage tool to handle this. We also took the opportunity to look at our tools, and to mainstream them a bit by turning everything into PowerShell cmdlets (which are easy to call from a CMD console, if you're a PowerShell greenhorn like me).
So, over the course of the last three months, I created an insanely complex data model mapping layer that lets me trivially generate source files for nuget packages (a .nuspec file), MSBuild files(.targets and .props) where all the complex rules for how to handle virtually every situation and every possible thing that a package publisher would need to be able do, all from an extremely simple format (No XML!).
Why not simply extend the .nuspec format?
First of all, the .nuspec file is simply metadata --essentially a manifest for what's encapsulated in the package file. Given the complexity of everything we needed to do, packagers can't really can't be constrained to such a format, and consumers don't need all of that data when consuming the file.
Second, I'm sorry to say, XML Sucks. XML is OK when you want to have a persistence format that is primarily for programmatic consumption, and you occasionally want to be able to use it in a human-readable context, but past that, it's absolutely the wrong format for scripts and property files. I had already devised a file-format/script-format for CoApp tools in the past (the base of which we called property-sheets) and found that it was a great way of expressing what we needed. Sure, it's somewhat possible to have used YAML, JSON or some other basic persistence/encoding format, but they lacked some of the advanced expression features that I needed to be able to simply support very complex operations.
Our property-sheet format is a distant cousin of CSS -- the original format was essentially a way of describing properties that could be 'applied' to an arbitrary data model in the same way that CSS is applied to HTML. Three years of tweaking and rewrites and we've got the V3 of property-sheets that has some rather amazing behavior wrapped in a very simple and forgiving language.
A Sneak Peek at the tool to generate these packages.
We now have initial builds of the PowerShell cmdlets to build NuGet packages.
Caveats:
This is all pre-release code. Many bugs, and not entirely finished. Please be kind :D
Currently requires PowerShell 3.0 (which you can get for Windows 7 here )
Currently requires a nightly build of NuGet which you can get: http://build.nuget.org/NuGet.Tools.vsix
Grab the latest installer from http://downloads.coapp.org/files/CoApp.Tools.Powershell.msi ... I'm constantly updating the build there all of the time, and the latest is always there.
Lousy Installer -- Until I get to resuming builds of CoApp, the tool is simply an MSI installer, with no UI. Install it, reboot (or kill and restart Explorer -- we updated the PSModulePath, and it doesn't refresh Explorer's copy of the variable until restart) Sorry, I wasn't gonna spend a ton of time on that with CoApp V2 right around the corner.
Once you've got it installed you should be able to start PowerShell and check that it's available:
404 Not Found
Error: Not Found
The requested URL / was not found on this server.
It has a poor-man's update facility built in:
404 Not Found
Error: Not Found
The requested URL / was not found on this server.
Of course, MSI can't update locked files (which are locked if you have PowerShell running), so you have to close your PowerShell windows before the Installer can continue. Or, use the -KillPowershells switch, and it will try to kill all the powershell processes for you.
- No Docs. I'm trying to get some docs written, and some examples done. Coming Soon.
If you're desperate, you can check out the current zlib and openssl examples but I highly recommend you join us on irc://irc.freenode.net#coapp so you can pelt us with questions.
The only other command you can use right now is Write-NuGetPackage
404 Not Found
Error: Not Found
The requested URL / was not found on this server.
Optimized for the happy-path. What's the 'happy-path' ? Things that work. Error messages are still a bit cryptic, and don't always lead you to the answer. Ping me on Twitter or IRC when something goes wrong, and either Tim or I will help you.
It's somewhere around a beta build at this point. Generally, it's mostly baked but we're still tweaking and adding to the package format.
Using native packages
Once you have that installed, I've got a public gallery of the native packages we're building for testing purposes which you can see : http://www.myget.org/gallery/coapp
The actual feed to add to NuGet is : http://www.myget.org/F/coapp/
A cry for help!
The code is in a state of complexity right now, that I think code contributions would be extremely difficult for someone to do. I'll walk you thru building it if you'd like, but I'm pretty much sure you'll melt your brain if you look too closely at some of my code :D
Even though we're in a barely-beta state at this point, I'd love for people to test it out with some of their native code, and help refine it as we go.
What I really need however, is some help documenting this stuff
All our docs are going to be on the CoApp site, and are in markdown format. If you want to help, it's pretty easy to fork the CoApp.org repository and edit the content. See the Tutorials section Contributing to the CoApp Project. I'd love some tutorials and reference docs written.
More Details:
There is a ton of complexity that I haven't explained or documented yet. I can't promise how fast I can write all of this stuff down, but I'll try to make a dent in it very soon.
Next Time : What's going on with the rest CoApp then?
View Comments
Package Management and the road ahead.
Dec 11 2012 by Garrett Serack @fearthecowboy
Tags news
Howdy!
This post has been a long time coming, the trick is, that a great deal many things have come up and it took some significant effort to work through it all.
First, let me state that CoApp is still alive and we're working to take it to better levels and really get things moving. We just had to take stock of everything, and to make sure that we're on the right track.
After going pretty much non-stop for well over a year on chasing our dreams, I was reminded:
"Life moves pretty fast. You don't stop and look around once in a while, you could miss it"
So, at the end of July, we stopped for a small vacation break during the summer, and we decided to take the opportunity to look how CoApp fits with other things in the package management ecosystem on Windows, and try to make sure that we're doing the right thing, and trying hard to work and play well with others.
I spent a lot of time talking with people one-on-one inside and outside of Microsoft. I spoke with so many people involved in many different places who have some sort of interest in installation or packages, or building software.
Several thoughts emerged, and it was clear that they needed to be accounted for:
Not everyone thinks about packaging the way that I do.
Funny thing. Not everyone sees the world as I do. And worse, when my vision doesn't synch well with theirs, they tend to be less likely to want to do things my way.
Now, it's not that I didn't understand that, but rather, I think that I was a tad focused on my vision as possibly everything that everyone would need, and one way or another, I'd provide enough value that they'd just have to see it my way.
This of course, also pushed me to trying to do more all at once than I was able to do... More about that later.
Along comes Nuget, which changes how developers work with managed libraries.
And then a bit over a year ago, Nuget shows up. But... it didn't do anything that I thought was useful to me, and so I really didn't invest any time or effort into it. It's a developer-oriented package manager for managed (or web) libraries. Hardly useful for supporting native code like OpenSSL, zlib, and the like, right?
Chocolatey simplifies doing things we were all doing anyway.
A few months later, Chocolatey makes the scene. Chocolatey uses Nuget to push around scripts that automate the installation of so many things. In CoApp, we called these faux-packages -- not really a proper packaging, but an effective method to install things that aren't really easily repackaged.
WiX is still the King
CoApp itself uses WiX to actually create our packages, so it's not like I didn't realize it's value or underestimate the extensive adoption that it has. Where I really didn't stop and think was how the 'Monolithic' installer model is really quite important, and how that relates to the work that CoApp is attempting to do.
Trying to do too much
I think the hard part of working on solving a giant problem is that sometimes, it's not all that easy to see the smartest path to accomplishing what you really need to. I know that I didn't really have good focus on a very small number of scenarios, I was trying to balance far too many things at one time.
Establishing an ecosystem that works together.
I started thinking about how all of this fits together and how we (as an ecosystem) need to be able to work together--and more importantly--still allow different systems to work how they please.
Many years ago, Kim Cameron came up with a list of "7 Laws of Identity". They outline some core fundamental principles that any Identity system should follow to ensure that everyone's (users, identity providers, and relying parties) security is maximized.
It occurred to me, that concepts from the Laws could be recycled in a way that reflects how we can define the general parameters for an installation ecosystem:
USER CONTROL AND CONSENT
Users must always be able to make the ultimate decisions about their system, and installers must never do unauthorized actions without the user's consent. Essentially, we really want to ensure that changes that the user doesn’t want aren't being applied to their systems. This means that the that installers should always provide a clear and accurate description of the product being installed, and ensure that the user is in control of their systems. User interfaces or tools that obscure or break this trust with the user should be avoided. Ideally, user interfaces should strive for some amount of minimalism, not be serving up a collection of pedantic screens which users tediously press 'next' thru. Less UI means that users are far more likely to pay attention to what's said.
Personal Opinion: I guess at the same time, I should point out a particular gripe of mine, especially with open source software installation on Windows. The proliferation of EULAs and Licenses masquerading as EULAs in the installation process should stop. Many OSS licenses don't actually have any requirement upon the end-user to agree to the terms of them before installation, so please stop asking for people to 'agree' just to make it look like you have a 'professional' installer.
If you actually have a requirement to record an acceptance of license, perhaps you should be doing that upon first use (or whatever activity actually requires the acceptance of the license)
MINIMAL IMPACT FOR A CONSTRAINED USE
Changes to a system should aim to offer the least amount of disruption to the system. Installing unnecessary or unwanted components adds to bloat, and will increase the potential attack surface for malware.
Personal Opinion: There is a category of software out there that has opted to provide their software free, but heavily--and often with great vigilance--attempts to install toolbars, add-ins, or other pieces of trash software that serve only to funnel advertising to the user. Others nag the user to change their default search settings, or their browser home page for similar purposes. These behaviors are abusive to customers, and should be avoided at all costs.
PLURALISM OF OPERATORS AND TECHNOLOGIES
The ecosystem should easily support many different technologies, there is no one-size-fits-all answer. Software comes in all shapes and sizes. Any well-behaved individual packaging or installation technology should be welcome to participate. Choosing one technology over another should be left to the publisher. Pushing this to the logical ends means that any attempt to unify these should permit and encourage use of any part of the ecosystem.
TRANSPARENCY, ACCOUNTABILITY, AND REVERSABILITY
Installation technologies should never obfuscate what is being done, should never place the system in a state that can't be undone. Again, keeping in mind that the target system belongs to the user, not the publisher, end users should be able to expect that un-installation should remove without issue or require any additional work to clean up.
Personal Opinion: On a slightly tangential note, I'd like to talk about rebooting the system. Windows Installers seem to be overly-eager to reboot the OS, either on installation or uninstallation. Now look--there is a very small class of software that can actually justify having to reboot the system. 99%+ of software should be able to deal with file conflicts, proper setup, manage their running processes or services, manipulating locked files, remove their temporary files, and all of those other things that you think you need to reboot the system in order to finish the work. If you need help on doing this, ask. You'll be doing everyone a great service.
FLEXIBILITY OF INSTALLATION SCOPE
Ideally, a given package should be able to install into different installation scopes (OS/Global scope, Restricted/User scope, and Local/Sandboxed scope) and support installation into online and offline (VM Images) systems. Packaging systems should consider how they can help products to be fully installed in these scopes.
INSTALLATION IS NOT CONFIGURATION
Software installation on Windows has since time began, been conflating configuration with installation. This approach introduces several painful problems into the software installation process:
- This increases the amount of UI during installation, which only leads to additional confusion for the end user.
- Users may not know the answers to configuration questions, and are now blocked until they can find answers.
- Configuration during installation is nearly always significantly different than the process to configure (or 're-configure') the product after installation. Again, confusing to the user.
- Migrating a working configuration to another system is harder when you have to answer during installation. Configuration should be easily portable between installations.
- Increases friction for end-users who are trying to automate the installation of software for large numbers of systems.
Really, don't be that guy.
RESPECT THE RESOURCES OF THE TARGET SYSTEM
Software publishers need to respect the system to which their software is being installed. You don't own that system, the end user does. Common scenarios that can be disrespectful
Launching straight from the installer -- Installation should not be considered good opportunity to launch your application. Similar to configuration issues, this is frustrating to end-users who are looking to automate the installations, and can introduce confusion for users who may not have expected that.
Automatically starting software at system start -- The proliferation of software that insists on starting up with the OS automatically is getting out of control. Software that wishes to launch at start-up should get explicit opt-in consent from the user (after the user has launched the application), not require the user to hunt down the option from a sea of configuration settings to disable it. Oh, and not providing a method to trivially disable auto-start is very bad.
Checking for software updates -- There are two acceptable methods for automatically checking for software updates. Preferred: checking from within the application itself (ie, at startup) and elegantly handling update and restart. Acceptable: Launching an update checker via a scheduled task, checking and then exiting. Wrong: Auto-starting a background or tray-application to constantly check for updates.
Personal Opinion: This last one is particularly frustrating. Since Windows doesn't currently have a built-in 3rd party update service (like Windows Update) that will on a schedule check for updates, download and install them, many companies have resorted to running bloated, wasteful apps in the background, waiting for updates. This is terribly disrespectful to the end user's system, and offers absolutely nothing of value to the user that a scheduled task wouldn't accomplish with less effort.
CONSISTENT EXPERIENCE ACROSS CONTEXTS
Finally, regardless of underlying technology, there should be a common set of commands, tools and processes that allows users to install whatever software in the way that they'd like. Currently, we see that individual installation technologies are all headed in different directions, which makes automating the installation of some pieces of software a nightmare. We as a community need to have the ability to bring all of these pieces of software together without having to manually script each individual combination.
The Road Ahead
Whoa, this blog post kinda got away from me.
Tomorrow, I'll do a post about how I think we can live up to the ideals in these laws, and where we are with CoApp, and how we're gonna get where we want to be.
View Comments
Released, at last
Jul 19 2012 by Garrett Serack @fearthecowboy
Tags news
A little over two years ago, I launched this project.
I started with an idea. No code, no full plan, just this idea that I wanted to fix a fundemental gap in the way that open source software finds its way onto Windows.
I sought out the Outercurve Foundation--still sporting that new Foundation smell--as our home. At the time, it was the one place that we could incubate this idea without undue burden on my corporate overlords, and still retain the complete and total freedom to take this project where we wanted to. Even now, CoApp is the still the only Outercurve project to not start with a code-contribution and a rights assignment.
From there, I brought together 15 people from open source commiunities and shared my initial vision. We spent three days refining that into what eventually became this shared vision of what was needed to close this gap. A lot changed from that first day, and over the course of of the last couple years, it would change even more.
Biting off more that we could chew
My pappy once told me "It's only after you've been thrown from the horse, that it's easy to see why". Which was his way of saying that sometimes it's impossible to see what's not going to work until you've done it wrong.
Something that I didn't realize until quite recently, is that "starting-from-scratch" was even harder than it sounds. For the first year, I was the only full-time project member, which made it really difficult for others to contribute at the same pace as I could. Even though the barrier for others to just jump in and help was pretty high, there still was a few folks who were able to pitch in here and there.
There was also the ever-exspanding list of things that needed doing to make the project successful. We needed a website, a wiki, tools to build packages, tools to help build projects, shallow forks of projects, digital signing tools, bootstraper technology to get the engine onto the user's machine, a service to accept packages and produce feeds, a content-distribution-network... all this, on top of the massive undertaking of a new package manager itself.
And a year passes...
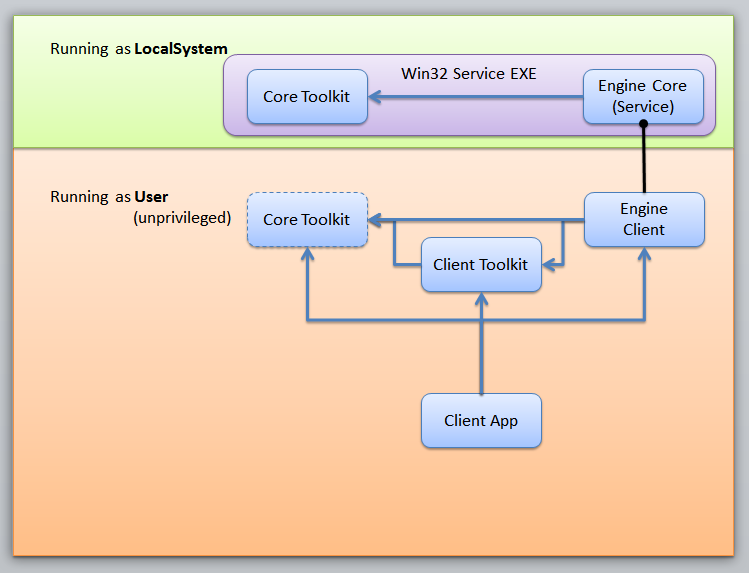
Last summer, we reached what I called "Beta" -- it was the point where we had a complete, end-to-end functional system, though buggy as heck, but had what I considered to be the core functional bits...Except there were a couple critical failings in the way that it worked with Windows Installer, and we needed to make a fundemental change in the infrastructure--changing the core engine from working as a library to a Win32 service.
That lead to "Beta 2" last fall, and "Beta 3" in late winter--each step making the core scenarios each one step closer to reality. With each new build we were still discovering things about the packaging and installation processes that encouraged us to continually refactor parts of the system.
When we released our "Release Candidate" a couple months ago, we had reached a pretty stable state. The 'happy-path' was quite functional, packages could be created, installed, removed, and our repository of shallow-forked projects was growing constantly.
We made it!
Finally, after a half million lines of code (spread out across all of our tools and libraries) and a few thousand builds, we've reached our 'Release' milestone.
We've got a stable, moderately robust toolset to build, consume and update packages in a frictionless way.
I won't jump out and say that it's bug-free yet, but the primary scenarios all seem to work pretty good, and we'll be constantly fixing bugs and updating it as we go forward.
And we're not even done yet.
Where do we go from here?
Over the course of the next few weeks, we'll be constantly publishing new content here, starting with some much-needed 'how-to' and tutorials, as well as additional documentation and instructions on how to actually build packages, troubleshooting, and even building CoApp itself and pushing changes (so that anyone can fix bugs and push back changes)
As well, we'll be working on our new feature roadmap and figuring out how to implement all that too!
View Comments
Google Summer of Code
Mar 22 2012 by Garrett Serack @fearthecowboy
Tags gsoc
You may have heard that the Outercurve Foundation has been accepted as a Mentoring organization for Google Summer of Code.
The Outercuve GSoC ideas Page
What we need:
Students to build code! Please get the word out that CoApp (and Opensource on Windows in general) needs students for GSoC . Student applications start March 26th
Mentors -- I've got 3 or 4 folks already volunteered; if we get a few students, we may need more. Anyone who can act as a mentor, I'd ask that you APPLY IMMEDIATELY so we can show strong support for our project. Request to be a Mentor for the Outercurve Foundation. (Mention "Garrett told me to tell you that I'm applying as a mentor for the CoApp project" in the message)
More Ideas -- We can always use more ideas of things to build for #CoApp ... (not just making shallow-forks), but some new innovative tools.
Student applications open March 26th (four days from now!)
We need action on this ASAP.
The More Students and Ideas we have, the more slots we should be able to get!
View Comments
Getting Started with Autopackage
Mar 17 2012 by Eric Schultz @wwahammy
Tags gsoc
One of CoApp's recommended Google Summer of Code ideas is a CoApp Package Maker GUI (Reference #2012-001). Currently package creation is performed with the autopackage which takes .autopkg files as input. Creating these .autopkg files can be rather daunting we intend the GUI tool to streamline the creation and management of these files.
To help students interested in GSoC (and anyone else new to the project), I'm creating a set of tutorials teaching the basics of autopackage. I'll start with preparing your development system and creating very simple packages in this post.
Preparation
Autopackage currently has a few requirements outside of the CoApp ecosystem. You'll need to install these requirements before moving forward:
- WiX Toolset v 3.6 Beta
- Windows SDK v7.1
While not explicitly required yet, it's highly recommended that you install Git at this time as well.
After installing those, we have your system ready for Autopackage. Autopackage is part of the CoApp.Devtools package and can be downloaded from the CoApp package directory. Download this file and follow the installation prompts.
Creating a signing certificate
All CoApp packages are required to be signed. In order to create a package, you need to have a code signing certificate. A simple shell script used for creating a test code signing certificate is available as a CoApp package called MakeTestCert.
To install MakeTestCert, run the following command at an administrator command prompt:
404 Not Found
Error: Not Found
The requested URL / was not found on this server.
Now we're going to create a test certificate. Once MakeTestCert is installed, open the Windows Sdk Command Prompt as an administrator. Once there navigate to a folder where you'd like to place your test certificate and type:
404 Not Found
Error: Not Found
The requested URL / was not found on this server.
You'll be asked for a password, which is used to protect the private key for signing. Once you've entered a password and the command is complete. There will be two files created in the folder called "test_cert.cer" and "test_cert.pfx." The first one just contains the public key and the second contains the public and private key and is used for signing packages. We'll need this later!
Next let's make sure the key is added to the trusted root authorities on the computer. Run the following command:
404 Not Found
Error: Not Found
The requested URL / was not found on this server.
This places your test certificate into the root of your certificate store on your computer. Additionally, your
Creating the sample package
Download the sample package and extract it.
You could use git to clone the repository at (https://github.com/ericschultz/MakeTestCert/).
This is a simplified source for the MakeTestCert package we installed earlier. In the root, you'll find a set of files and folders. Ignoring the readme and the files and folders used by Git, we have one file, MakeTestCert-Sample.cmd. This is the main shell script used by MakeTestCert.
You'll also see the COPKG directory. In the root of the source of every coapp package, you'll find a COPKG directory. This contains the information necessary to build and create the package. Inside that folder is one file, in this case called MakeTestCert.autopkg, which defines a package. Let's open that file for editing.
.autopkg files have a syntax similar to CSS files. In future posts, I'll discuss what all the rules mean but for now let's do a simple modification to the file to get our feet wet. Find the following line:
404 Not Found
Error: Not Found
The requested URL / was not found on this server.
Since you're the creating the package, you might as well get some credit as the publisher. :) Replace YOURNAME with your actual name and save the file.
Now that we've finished the autopkg file, let's build the actual package. Navigate back to the root and run the following command:
404 Not Found
Error: Not Found
The requested URL / was not found on this server.
After the command complete (it takes a while the first time while autopackage finds WiX), you will have a file called MakeTestCert-SAMPLE-1.0.0.0-any.msi in the COPKG directory. This is your package! Run this MSI and you'll install you're personally created copy of MakeTestCert-SAMPLE. Since the autopkg file puts MakeTestCert-SAMPLE, you can run MakeTestCert-SAMPLE from any command prompt.
The --remember argument isn't required but you'll probably want to use it. Why you ask? --remember saves the certificate and your password into the registry (in an encrypted form of course) for use by autopackage and a few other CoApp tools. Once you've used --remember, you won't have to provide a certificate path or password in the future for tools that need them. In that case you could run
autopackage COPKG\MakeTestCert.autopkg
Normally, Autopackage can be run from any command prompt but a bug in the CoApp engine requires Autopackage to be run from an elevated command prompt. This bug should be fixed in the next week.
Where do I go from here?
Over the next few weeks, I will have additional tutorials that describe more features of Autopackage. In the mean time, play around with autopackage and look at the .autopkg files used by CoApp and by the packages in the coapp-packages organization. Additionally feel free to email me at (wwahammy@gmail.com'>wwahammy@gmail.com), contact me on Twitter @wwahammy or visit our IRC channel. Feel free to ask questions! We know CoApp can be a bit daunting (that's why we have the GSoC projects!) and we're very interested in helping!
View Comments
Preview of CoApp GUI - Part 2
Feb 21 2012 by Eric Schultz @wwahammy
Tags gui,updater
Part 1 of CoApp GUI preview
Today I'm going to summarize the mockup work I've completed on the general package manager for CoApp. Before I start, it's important to understand a few design decisions and the reasons for them.
During the design of the UI, the general package manager is both a package manager and something more broad, what we call a product manager. As you may recall, a CoApp package is uniquely identified by a name, a processor architecture, a version number and the public key token of the publisher. For certain advanced uses, a user might need this information but for most uses a user just wants a particular piece of software and to have it updated, ie: you want the latest version of Firefox and I want it to stay updated. For this purpose we have a simpler view of a set of packages from the same publisher with the same name which we call a "product." Most interactions with the CoApp GUI is with software at the product level instead of the package level. This isn't to say that interacting directly with packages isn't allowed or easy to do, a user certainly can and it's straightforward to do.
As we walk through the screenshots, you'll notice the similarity to the Windows App Store. This is not coincidental for a few reasons. First by making it as similar as possible to one of the primary methods of software distribution on Windows 8 we feel users will feel at home working with CoApp. Second, we know the App Store design has gone through numerous usability studies and redesign to become as straightforward for the end user. Considering we have very few resources to perform that kind of research, it seems practical to utilize the research that's already been performed.
With all that out of the way, let's get to the screenshots and walk through of the GUI.
Note: logos are used for illustration purposes only. While we certainly hope all of the open source projects illustrated will have CoApp packages, this isn't intended to indicate that they necessarily will.
Product/Package Manager

This is the home screen of the product manager that the user will see when they start the software. In fitting with Metro principles, the list of groups scroll left to right. The groups come from two places. First each package will be required to set a category. Secondly the user can use the Add a Feed button on the top right (or from the Setting screen) to add more feed urls. These feed URLs will be added to the home screen. Not shown is a link near the top right that would shows the user all installed products.
Universal Search
Not visible is that search is pervasive throughout the GUI. Simply typing begins a search (as long as a textbox doesn't have focus of course) or continues a search . In fact the search screen is reused for the installed products screen and the screen for showing all products in a category and from a feed.

The screenshot above illustrates the design of the search screen, in this case it's showing all products in the Games categories. Above the list of products are filters (no the filter doesn't really do anything in the mockup :). CoApp utilizes a filtering concept we're calling "frictionless filtering." To add a filter, the user presses the the create filter button with the plus on the right side of the list of filters. After pressing the button a menu drop down with a list of possible attributes that a user can filter based on and an appropriate UI elements to create a filter for the given attribute. Once the user creates a filter, the filter replaces the button that was originally pressed. A new create filter button is created to the right of all the filters. To delete a filter, the user presses one of the previously created filters. The system is straightforward, intuitive and extremely powerful.
Once the user clicks on a product, the following screen will be displayed:

Should the user click the name of the publisher or one of the contributors, a bit of UI will be display providing information about the selected entity:

When the user sees the details tab, it will look like so:

The details tab provides more advanced information that the user might be interested in. Selecting one of the package versions will send the user to the screen for that package.

Reviews for products are actually a combination of reviews for every package in a product. New reviews for a product are considered reviews of the latest package. This allows users to handle reviews in a way that feels natural but still provides all users with package level feedback should they want it. The slider above the reviews allows the user to filter based on how recent the reviewed version is.

Installing a product with dependencies will ask the user whether they want all the dependencies of the product. As you can see in the upper right corner, there is a link, in this case titled "4 packages installing" to see what packages are being installed. If there is an error during installation, the link will note that an error occurred, turn red and an exclamation point will slowly flash next to the link.

If a product or one of its dependencies is blocked, the user will be asked to unblock the blocked packages.

On the package page, the details tabs show slightly different information that the user might want to know versus the product page. Specifically, the license for the package is shown and which versions this package is binary compatible with.

The installing screen is again available from pressing the link in the top right hand corner of the application.
Again, this looks neat but when do I get it?
The current timeline is to have this full GUI available for the release candidate which is around 8 weeks out.
Any feedback you can provide would be greatly appreciated! Please provide feedback on this post, the CoApp mailing list, the CoApp IRC channel or to me via Twitter.
View Comments
Preview of CoApp GUI - Part 1
Feb 17 2012 by Eric Schultz @wwahammy
Tags gui,updater
Over the past few weeks, I've begun working full-time on creating a lo-fi mockup of the CoApp GUI as the beginning of my work on the GUI. At this point, I feel it's appropriate to share what's been accomplished, where we intend the GUI to going and how long I anticipate that taking.
The mock up was made in Sketchflow in Expression Blend. Sketchflow provides us with a good enough idea of how the interface might work but it has low enough fidelity that we don't get mired in minute design details. This is not the final product but it gets us in that direction.
The GUI consists of two major parts: an update client and the general package manager. This post will focus on the update client, while a future post will discuss the package manager.
Update Client
The update client is used to automate updates and upgrades of CoApp installed software. The update client follows a schedule and runs regularly in order to update CoApp software when needed in much the same way as Windows Update. Indeed, its user interface is very similar to Windows Update. The primary purpose of this is to put users at ease when they use the CoApp Updater.

A user can get into CoApp Updater in a couple of ways. First they could manually start CoApp Updater if they were interested in checking if any updates existed for their software. Second when CoApp Update automatically runs in the background as scheduled it places a small icon in the system notification area. The user may double click that icon to open the CoApp Updater.
When user manually starts the CoApp Updater, the above screen is where they start. Once that's completed they go to the either a screen saying no packages are available or that packages are available.

The above screen shows when no package are available. The user can recheck for updates if they'd like. If there are updates, the user sees the following screen:

In this case, the user can either click on the link titled "5 updates available" to view the updates and upgrades or can press Install to install all the selected updates.

When the user views the updates they see the screen above. Again this is very similar to Windows Update. There are a few features that are not shown. One feature is that the user could block a particular update by right clicking on the name of the update. Additionally based upon community feedback during our conference call, I will be adding a method for the user to see which packages depend on a particular package to be updated. A user may want to know whether an updatable package, say OpenSSL, is used by another particularly vital package, say PHP. The user for whatever reason may want to verify that no packages used by PHP are ever updated. This allows the user to perform this verification.
When the user clicks install, the following screen is shown:

Again, this is very similar to the Windows Update installation screen.
That's neat, but when do I get this?
The update client is on a very aggressive schedule with the plan of having it committed into the main CoApp repository in about three weeks and to be officially released in the CoApp 1 RC.
Because of this timeline, if you want your suggestions added into the Updater for this initial release, time is of the essence! Please provide feedback as soon as possible on this post, the CoApp mailing list, the CoApp IRC channel and/or directly to me on Twitter
View Comments
Important CoApp Conference Call for FEB 17 2012
Feb 16 2012 by Garrett Serack @fearthecowboy
Tags news
There will be a CoApp Conference call on Friday, however, I'm going to move it up an hour, since I have a hard stop at 11:00am.
So the conference call will be at 9:30 am PST
| Topics: | |
|---|
| CoApp Beta 3 Announcement | |
| CoApp UI design for Updater and GUI Package Manager | |
| More on Google Summer of Code | |
| More! | |
Like always, everyone is welcome!
View Comments
Conference Call for FEB 10 2012
Feb 09 2012 by Garrett Serack @fearthecowboy
Tags news
As per usual, there will be a CoApp Conference call on Friday 10:30 PST
| Topics: | |
|---|
| FOSDEM News | |
| Code Signing Certificates update | |
| Google Summer of Code | |
| Push to get Beta 3 released | |
| More! | |
Like always, everyone is welcome!
View Comments
Today's Conference Call
Jan 13 2012 by Garrett Serack @fearthecowboy
Tags news
As per usual, there will be a CoApp Conference call today 10:30 PST
| Topics: | |
|---|
| Some ideas about packaging: | |
| - libraries for multiple compilers/standardiazing library names | |
| - developer libraries | |
| - ptk targeting multiple compilers | |
| The One True Build Machine To Rule Them All | |
| Ideas about 'repackaging' software | |
| FOSDEM 2012 presentation ideas | |
Everyone is Welcome!
View Comments
How Does CoApp Handle Dependencies?
Jan 10 2012 by Garrett Serack @fearthecowboy
Tags design
Recently, on the mailing list, Mateusz Loskot asked the question:
Perhaps it has been discussed and solution's already established,
but I'm wondering how CoApp is going to solve dependencies between
packages?
Well, get your pencils ready kids, 'cause I'm about to drop the knowledge hammer down.
CoApp (over the longer term) handles dependencies in two ways:
Fixed dependencies and Flexible dependencies. Fixed dependencies are specific bindings to another package (Package B-1.0.0.0-x86-AAAABBBBCCCCDDDD requires Package A-1.0.0.0-x86-DDDDEEEEFFFF1111). Flexible dependencies are far more fluid, and simply state that "this package requires any package that satisfies feature-XYZ with a version matching range NNNN".
Fixed dependencies are tied very tightly to how Windows' Side-by-Side technology works. Each package has a name (e.g. B), version (e.g 1.0.0.0), platform architecture (e.g. x86), and a public-key-token (e.g. AAAABBBBCCCCDDDD, which is calculated from the hash of the signing key of the package-publisher's certificate). These create somewhat rigid requirements of other packages, where the only flexibility is that the publisher of a package can specify that a newer version of a package is binary-compatible with an older version, and should be used instead. In Windows, the binary-compatibility expressed by packages is called the publisher-policy.
In CoApp, we refer to this as the compatibility-policy. When a package asks for a version of a package, the package manager looks for the highest version of the package that satisfies the dependency, given the compatibility-policy. For example if a package binds to zlib-1.2.0.0-x86-AAAABBBBCCCCDD , and the highest binary-compatible package is zlib-1.2.7.11-AAAABBBBCCCCDDDD , CoApp will attempt to install the later package. This does seem to place a great deal of trust in the publisher of a given package--but really, if you're trusting them by making a dependency on them, you should be trusting them to make sure that they are not breaking binary compatibility when they say they are not. Conversely, publishers should be extremely careful not to break binary compatibility when publishing updates.
| | Things your OS never told you about version numbers | |
|---|
| | You may have noticed that CoApp version numbers are always represented as a four 16-bit positive integers, containing [major-version].[minor-version].[build-number].[revision]. For example, version 1.5.1254.0 indicates 1 as the major version number, 5 as the minor version number, 1254 as the build number and 0 as the revision number. Windows Side-by-Side technology (and it's sibling, .NET assemblies) requires this standard for versioning everything.
When Side-by-side is asked to find an assembly of a given version, it first looks at just the [major-version].[minor-version] of the assembly, and checks to see if there is a publisher-policy for that version combination. If there are any policies found (as there can be several), it then checks the version ranges in the policy to see if the requested version has been redirected to a new one.
From this behavior, you can infer that the designers of SxS generally intended that binary-compatible libraries would be constrained to the same major/minor versions, as you'd have to explicitly create a policy for every major/minor version that you wish to redirect (which is possible, but not encouraged). Those of us in the real world realize that controlling these numbers is not always as easy as that, so CoApp tries to make building policies bridging major/minor versions easier, and hides the details. | |
| | | |
When the package manager resolves the dependency tree where all the dependencies are Fixed, it does so in a predictable, fault-tolerant way. By examining the publisher policies, it works it's way back from the most appropriate version down to the least appropriate version. The most appropriate is the highest version that has a compatibility-policy that covers the given version, and where that package's entire dependency tree can be satisfied. If a failure happens during the downloading of the dependencies, or during the installation of one of the dependencies, that package gets marked as unable to be fulfilled for that installation session, and the package manager starts back at the top, and tries to identify the best package that can be fulfilled. This form of dependency resolution is always straightforward and doesn't require any special judgement or decision making ability, since every installable package has a very explicit expectation of what it requires.
Some fundamental difference between CoApp and package management resolution systems found on other platforms:
| | | |
|---|
| | CoApp packages never collide. Each and every package can be installed side-by-side with each other, and while one may be 'active' for purposes of a given configuration, the presence of another version of the same package can never result in the failure of it's sibling. | |
| | CoApp packages are always strong named. With the name, version, platform architecture and public-key-token, no package can be poisoned/broken by installing a package from another publisher. | |
| | With no possibility of package collision or conflicts, we have no need to support negative conditions on package dependencies (ie, install A & B unless C is installed.) This removes an order of complexity in package resolution. | |
We also have the ability to place markers on packages that affect resolution in a few ways:
| | Markers | |
|---|
| | Requested packages are packages that the user explicitly asked for. For example, I wanted to use OpenSSL-1.0.0.0 and it brought in zlib-1.2.5.0. OpenSSL is a requested package, zlib is not. When upgrading, a requested package can be upgraded to a newer version that may not be binary compatible (since you don't have a binary dependency you're breaking with installing a new one) | |
| | Required packages are packages that are the result of a dependency resolution. In the previous example, zlib is a required package. These can be automatically be upgraded to a newer, binary-compatible package. | |
| | Frozen packages are ones that the user has specifically stated that it is not to be upgraded, for whatever reason | |
| | Blocked packages are ones that the user has specifically stated that it is not to be installed, for whatever reason | |
Flexible dependencies on the other hand, are not yet implemented in CoApp, so even this definition is somewhat fluid. Generally, we're looking to make sure that we can have packages that simply state things like "I need any version of a python interpreter", or "I need a version of Java greater than Java 5" . Exactly how these are specified is still a topic for discussion, and I'm eagerly accepting ideas and feedback for how this plays out.
This is where it's going to get a little bit dicey, and we're going to have to build a set of rules to determine the most appropriate course of action.
| | Questions about happy package resolution | |
|---|
| | When two packages can satisfy a Flexible dependency, and you have neither installed, how do you choose which one to install? This ranges from the very trivial "I need any version of grep" to "I need a version of python 3.2+"
What criteria can we use to satisfy these dependencies (especially when the publisher has absolutely no preference) | |
| | CoApp prides itself (in the default case) of never requiring the user to make decisions for package satisfaction. Do we want to make it so that advanced users can be asked to choose a course for Flexible package resolution? | |
| | How do we set--or more appropriately, allow communities to--set standards for determining if a given package actually fulfills a given 'feature', and when in the event a package is found to not be adequately fulfilling a feature, how does the community push that feedback back to others?
Does this mean that a publisher should be able to say "I want any Perl 5 implementation, but not *Cheesy-Perl*" ? If so, what happens when we need to install a second Perl, just because a publisher didn't want or can't use the currently available one? Does that replace the 'active' installed Perl? | |
| | | |
I've looked at resolver algorithms like Libzypp and the general theories on the subject, and they appear to solve issues that our philosophical boundaries generally eliminate (XOR and negative conditions are unnecessary).
The only other random thought I've had is that there may be cases where a dependency tree is already installed for a less-than-most-appropriate dependency tree, but the package manager would try to update as much as it can. To me, this sounds like the packages are due for an update, but for whatever reason the user hasn't updated them. Should the package manager simply accept the given resolved dependency tree without additional installs, if possible?
View Comments